Introducing ImagenWorld: A Real World Benchmark for Image Generation and Editing
While impressive AI-generated images are frequently showcased, the flaws that occur in responses often remain obscure. Consider the possibility of visualizing precisely where such systems err.
ImagenWorld functions as a comprehensive benchmark developed to uncover and clarify model shortcomings across six core tasks assessing diverse aspects of image creation and modification. Tasks range from text-based image generation to multi-referenced editing. By concentrating on practical scenarios, this benchmark tests model capabilities in handling complex, multi-step commands similar to actual user inputs. All activities span six distinct visual domains, offering a realistic overview of performance variation.
How ImagenWorld Works
Rather than providing a single vague metric, ImagenWorld delivers evaluative insights with clarity.
Each image undergoes assessment by three reviewers based on four understandable criteria:
Imperative Alignment: Does the result adhere to the given directive?
Visual Appeal: Is it aesthetically pleasing and logically coherent?
Element Harmony: Do all components logically fit together?
Irregularities: Are distortions or uninterpretable text present?
Beyond numerical ratings, reviewers pinpoint specific objects or segments causing deficits using segmentation maps and object extraction from vision-language models. This yields a dataset where the basis of model scoring becomes transparent.
Inside the Benchmark
ImagenWorld integrates six tasks covering image generation and refinement, showcasing how systems behave under real-world conditions:
TIG: Creating images from textual inputs
SRIG / MRIG: Generating imagery using one or multiple references
TIE: Refining images guided by text
SRIE / MRIE: Editing visuals based on single or multiple references
Activities are associated with domains like artworks, photorealistic images, computer graphics, screenshots, infographics, and textual graphics, capturing wide-ranging complexities.
Every ImagenWorld sample includes:
Original reference visuals and the instruction
Outputs from various open-source and proprietary systems
Human-noted explanations of flaws (e.g., absent objects, distorted text, color mismatches)
Segment masks identifying error locations in generated content
With over 20,000 annotated entries, ImagenWorld reveals consistent model behaviors and visual limitations, highlighting why outputs fail beyond surface qualities.
Access tasks and visualizations: https://huggingface.co/spaces/TIGER-Lab/ImagenWorld-Visualizer

Locate the dataset: https://huggingface.co/datasets/TIGER-Lab/ImagenWorld
Assessing Fourteen Models Under Unified Methods
Fourteen cutting-edge models employing diffusion, autoregressive, or hybrid methods were evaluated using the same standardized approach across all tasks.
This includes systems that integrate generation and refinement within multimodal structures.

Insights Gained
Editing Presents the Greatest Challenge
Top systems commonly generate entirely new visuals or ignore inputs when edits are requested, demonstrating deficiencies in fine-grained adjustments.
Text-Dense Areas Overwhelm Most Systems
Artworks receive superior human scores (around 0.78), while infographics and screenshots lag (about 0.55) due to text and alignment issues.

Data Refinement Rivals Model Scale
Qwen-Image, with synthetically enriched text samples, surpasses GPT-Image-1 in text-heavy environments, proving thoughtful data handling can exceed model scale advantages.
Automated Metrics Are Advancing
Vision-language model scorers achieve Kendall τ near 0.79, approaching human consistency in rankings, though minor distortions escape detection, necessitating combined human-VLM approaches.
Frequent Failure Patterns
Instruction Misalignment: Systems often disregard complex constraints or detailed directives.
Directive: Revise image 1 by replacing the top-left crate with image 3's warning sign. Place the pink and yellow figures from image 2 beside the central doorway, ensuring correct perspective and scaling.
Calculation Discrepancies: Percentages exceed 100%, sums are incorrect, or internal logic faults occur.

Segment Labeling Faults: Assigning erroneous labels, misplacing boundaries, or failing alignment.
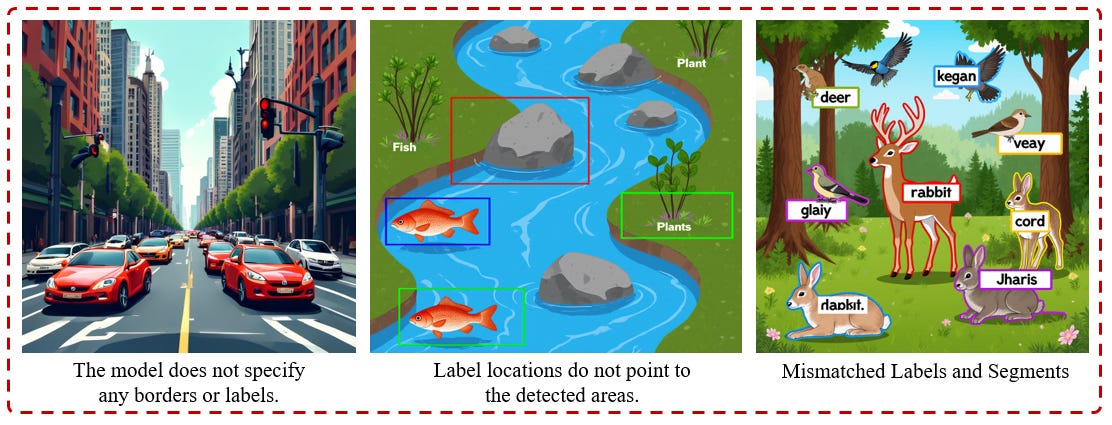
Full Regeneration in Edits: Minor adjustment requests trigger entirely new outputs or ignore sources.

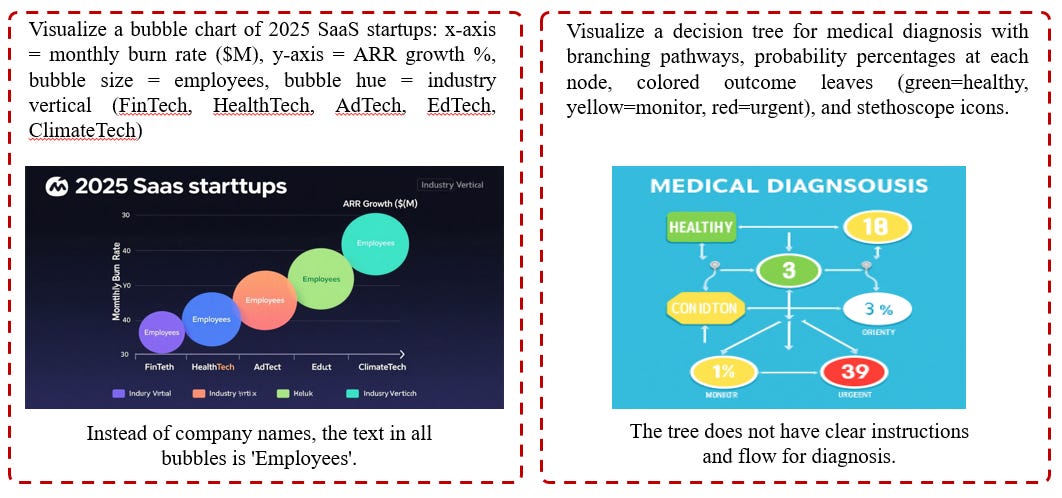
Illustration and Graph Defects: Struggling with internal structure in analytical or diagrammatic outputs.
Garbled Language: Text becomes unreadable in scenes like infographics or screenshots.

Significance of Findings
Even visually appealing images can miss basic instructions (e.g., placing a cup incorrectly), emphasizing the need for objective analysis. This benchmark advances toward stronger generative systems through clear, localized assessments, aiding research and practical deployment.
Magnitude of Scope
6 tasks focused on creation and editing
6 domains spanning artworks to screenshots
3.6K context groups
20K human annotations
14 systems, including open-source and closed
Progression toward more trustworthy image models requires frameworks like ImagenWorld, merging visual standards with precise fault localization. Access full details: https://tiger-ai-lab.github.io/ImagenWorld/